")
Wygładzanie wykładnicze
Metody wygładzania wykładniczego to szeroka klasa modeli o różnych założeniach i stopniach złożoności, które wywodzą się ze wspólnej idei tworzenia prognoz. Kolejne wprowadzane modele systematycznie powiększały możliwości tego podejścia, dając obecnie potężne narzędzie analizy szeregów czasowych.
Wspólnym mianownikiem wygładzania wykładniczego jest przypisywanie (wykładniczo) malejących wag obserwacjom historycznym przy wyznaczaniu prognozy przyszłej obserwacji. W najprostszej wersji równanie prognozy (modelu) miało postać:

dla t ∈{2,3,…,n}, gdzie α jest tak zwanym parametrem wygładzania przyjmującym wartości z przedziału [0, 1].
Modele wygładzania wykładniczego opierają się na rozsądnym założeniu, że przyszła wartość zależy nie tylko od ostatniej zaobserwowanej wartości, lecz całego ich szeregu, a jednocześnie wpływ wartości starszych (dawniejszych) jest mniejszy od wpływu wartości nowszych.
Obecnie w pełnej ogólności modele wygładzania wykładniczego charakteryzuje się przy pomocy czterech różnych parametrów (α,β,γ,ϕ) oraz rozważa się różne metody inicjalizacji (wyznaczania początkowych wartości modelu). W takim ujęciu parametr β kontroluje trend, parametr ϕ siłę tzw. wygaszania trendu, a wartość γ odpowiedzialna jest za sezonowość w modelu. Kluczową kwestią w całym algorytmie jest właściwe dobranie tych parametrów tak, by osiągnąć jak najlepsze prognozy.
Dodatkowo w modelu da się określić niezależnie charakter każdego ze składników – trendu, sezonowości i reszt – jako addytywny lub multiplikatywny (w przypadku trendu i sezonowości można też założyć, że składowa ta w szeregu nie występuje). Daje to – uwzględniając możliwość tłumienia trendu – 30 różnych rodzin modeli i ogromną liczbę możliwych kombinacji wartości parametrów.
W celu skrócenia zapisu wykorzystujemy standardowe oznaczenie ETS modeli wygładzania wykładniczego, gdzie: E – error (błąd), T – trend, S – seasonality (sezonowość) i w miejsce tych liter wstawiamy odpowiednie symbole określające typ składnika modelu: A – additive (addytywny), M – multiplicative (multiplikatywny), N – none (brak – tylko w przypadku trendu i sezonowości). Ponadto w przypadku trendu tłumionego dopisujemy literę d. Przykładowo model ![]() oznacza grupę modeli z addytywnymi błędami, multiplikatywnym tłumionym trendem oraz brakiem sezonowości.
oznacza grupę modeli z addytywnymi błędami, multiplikatywnym tłumionym trendem oraz brakiem sezonowości.
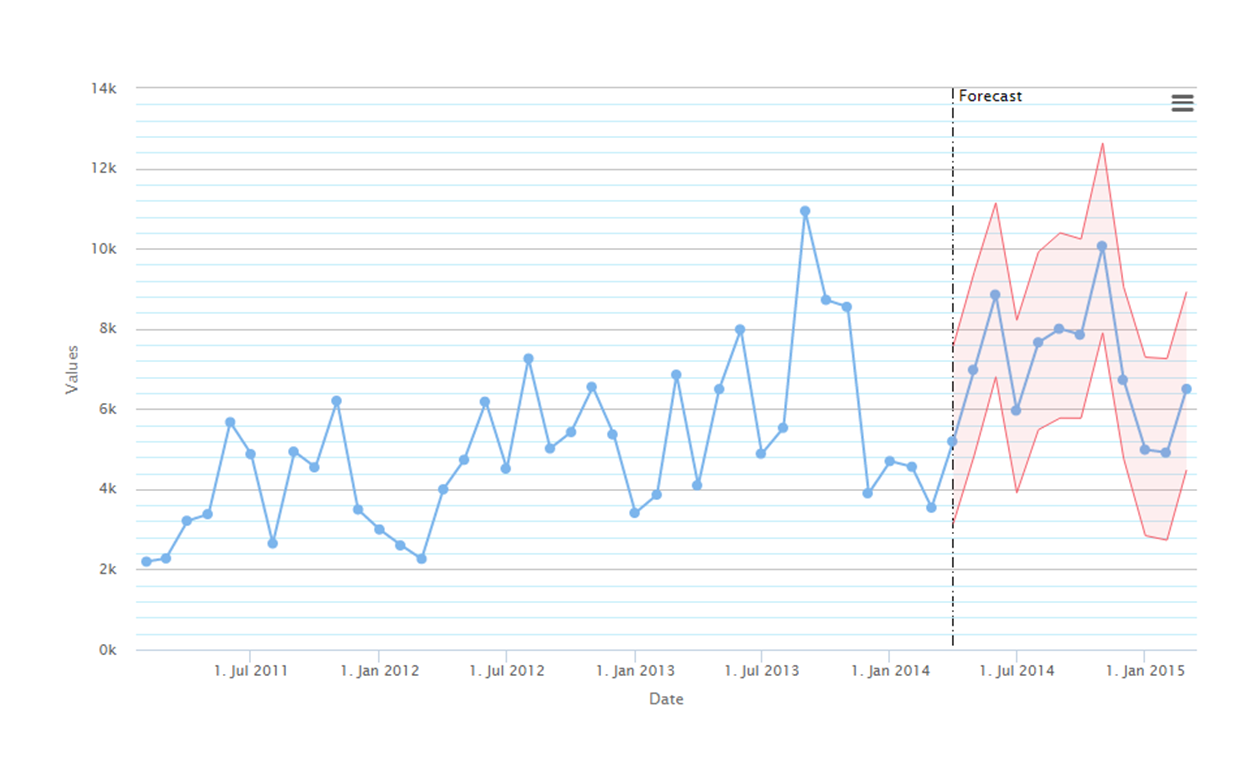
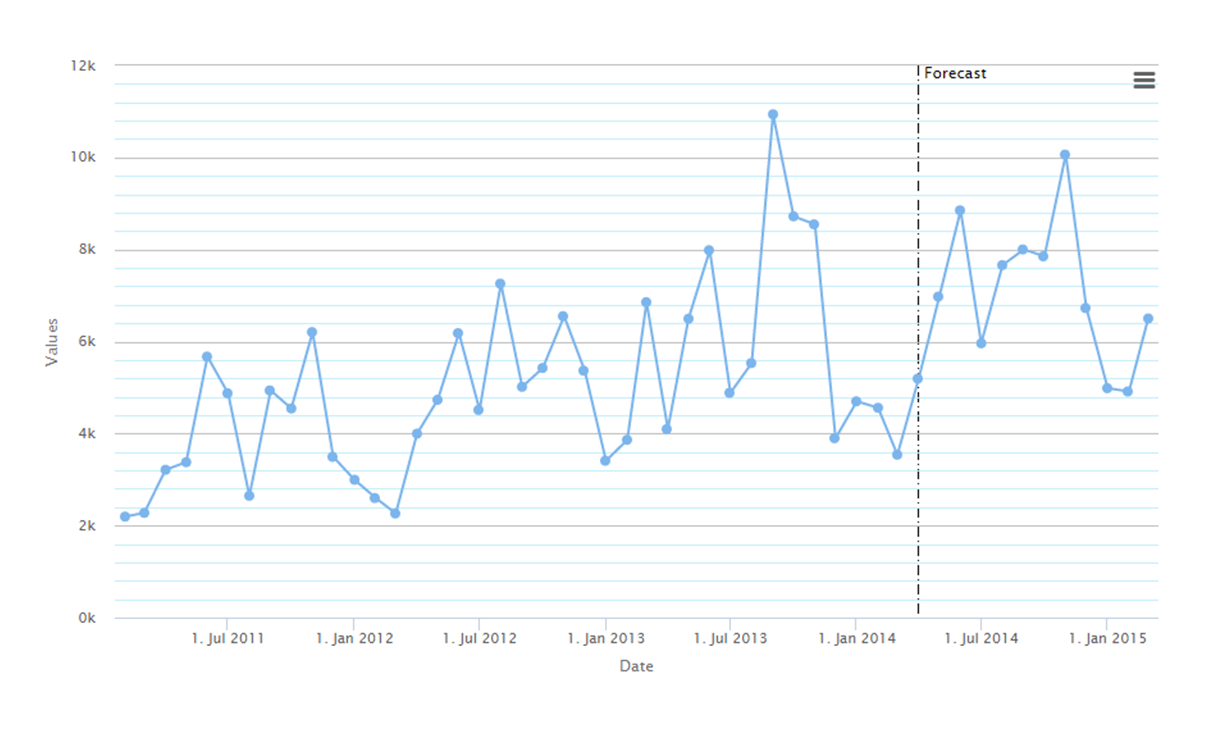 Prognoza metodą wygładzania wykładniczego – wybrano model AAM
Prognoza metodą wygładzania wykładniczego – wybrano model AAM
Wadą omawianych metod jest brak istnienia teorii wyznaczania przedziałów (obszarów) ufności dla prognoz. Firma Prologistica posiada jednak zaimplementowane symulacyjne wyznaczanie takich przedziałów.